Introduction
A Data Source in Data Intelligence is an indication of where the data is to be obtained from.
In most cases, it is bank data, which can be obtained from a backend system.
By default, finAPI OpenBanking Access is used for this.
There is also the possibility to import account and transaction data as JSON via the API.
Prerequisites
-
The major prerequisite is to have a valid set of client credentials:
client_idandclient_secret. -
A user has already been created
-
With self-managed user: Getting Started - User Management
-
With Process Controller: Obtain Authorization via Process Controller (recommended)
-
-
At least one account has already been imported via finAPI WebForm 2.0 (see WebForm Documentation)
-
Ensure that no account updates are still ongoing: Getting Started - Importing Bank Data - finAPI Web Form | Workflow as a real world example
TL:TR
Used Systems
-
finAPI Data Intelligence (finAPI API Documentation )
See Environments page for detailed information.
Used Endpoints
To create a report, at least the following endpoints are required:
|
Description |
HTTP Method |
Process Controller Endpoint |
Link to API Doc |
|---|---|---|---|
|
Synchronize Data Source |
POST |
|
|
|
Get status of the Data Source
|
GET |
|
Process Overview
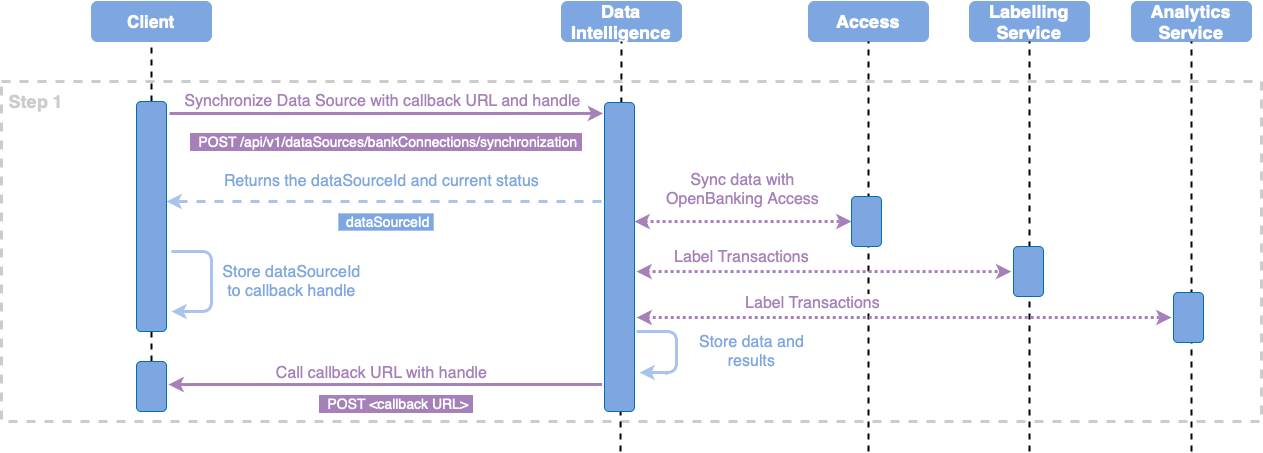
cURL Example
Translated into cURL it looks like the following:
Step 1 - Synchronize Data Source (cURL)
Before you can synchronize data in Data Intelligence, it must already have been imported via finAPI WebForm 2.0 or finAPI OpenBanking Access.
For synchronization, it is recommended that the callback is used to avoid unnecessary poll requests that can stress client and server systems.
Synchronization request example for full synchronization of the user:
curl --location 'https://di-sandbox.finapi.io/api/v1/dataSources/bankConnections/synchronization' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer <access_token>' \
--data '{
"callbackUrl": "https://domain.tld",
"callbackHandle": "38793e87-499d-4860-b947-2c2c8ab10322"
}'
The response looks like this:
{
"bankConnections": [
{
"dataSourceId": "4e760145-2e65-4242-ac33-488943528c93",
"creationDate": "2020-01-01 00:00:00.000",
"lastUpdate": "2020-01-01 00:00:00.000",
"externalId": 123456,
"bic": "COBADEFFXXX",
"bankName": "Commerzbank",
"bankStatus": "IN_PROGRESS",
"updateRequired": false,
"accounts": [
{
"accountId": "5f660145-2e65-4242-ac33-488943528c93",
"creationDate": "2020-01-01 00:00:00.000",
"lastUpdate": "2020-01-01 00:00:00.000",
"externalId": 123456,
"iban": "DE13700800000061110500",
"accountType": "CHECKING",
"status": "UPDATED"
}
]
}
]
}
Step 1.5 - Polling the status of the Data Source (cURL)
It is not recommended to poll the status. If you still want to do it, please make sure that there is at least a 200ms pause between requests.
Request to the Data Source status:
curl --location 'https://di-sandbox.finapi.io/api/v1/dataSources/{dataSourceId}/status' \
--header 'Authorization: Bearer <access_token>'
The response looks like this:
{
"status": "IN_PROGRESS",
"code": "SYNC_IN_PROGRESS",
}
As long as the status is not SUCCESSFUL, you cannot proceed with report creation.
Implementation Guide
See a full working project here: finAPI Data Intelligence Product Platform Examples (Bitbucket)
Code from this guide can be found here: finAPI Data Sources (Bitbucket)
Environment overview can be found here: Environments
The guidelines and the example project are written in Kotlin with Spring Boot. But it is easily adoptable for other languages and frameworks.
For the HTTP connection, we are using here plain Java HttpClient, to be not restrictive for the client selection and that everything is transparent.
Only the actual functionality is discussed in this guideline. Used helper classes or the models can be looked up in the source code.
However, we always recommend using a generated client from our API, which reduces the effort of creating models and functions to access the endpoints and eliminates potential sources of error.
To learn how to generate and apply the API client using the Process Controller "Create user and exchange with access_token" as an example, please see the Getting Started - Code Generator (SDK) Integration
Please also note that the code presented here and also the repository is only an illustration of a possible implementation. Therefore, the code is kept very simple and should not be used 1:1 in a production environment.
Example Code Flow Description
The flow of this example is, that the application synchronizes the data source as soon as the user is done with his connection of the accounts in finAPI WebForm or finAPI OpenBanking Access.
Further processing is done asynchronously by the callback.
As soon as the callback arrives again, it is checked whether the result is positive.
If the callback is positive, other actions like creating a Case can be done.
We are working with status updates in the local database. This database should be polled or streamed by the (frontend) application, to know if an error happened in the background or if the user can continue, because everything was successful.
Data sources are a central component and not just bound to reports. Therefore we create them in a neutral datasourcespackage: finAPI Data Sources(Bitbucket) (Data Source)
In this step, we create a simple service that starts the synchronization. In addition, we use a callback so that we don't have to poll for synchronization status.
First, we create a new class named DataSourceService. This gets the URL of finAPI Data Intelligence (incl. the base path /api/v1) and the domain of the own service for the callback.
As further classes we get the DataSourcesRepository and DiProcessesRepository passed. These classes are example database repositories. In the example, these classes are not discussed further because they only perform the required tasks in the example.
Last but not least we have an ObjectMapper which is used to map JSON into objects and vice versa.
The first function we create is createPostRequest(). This is passed the user access_token, the URI of finAPI Data Intelligence, and the body.
From the URI and the diURL, which we get via the constructor and the configuration, the method builds the final URL.
@Service
class DataSourceService(
@Value("\${finapi.instances.dataintelligence.url}") private val diUrl: String,
@Value("\${exampleapp.instances.callback.url}") private val callbackUrl: String,
private val dataSourcesRepository: DataSourcesRepository,
private val diProcessesRepository: ReportProcessesRepository,
private val objectMapper: ObjectMapper
) {
/**
* Create a POST HttpRequest.
*/
private fun createPostRequest(
accessToken: String,
endpointUri: String,
body: String
): HttpRequest {
return HttpRequest.newBuilder()
// build URL for https://<data_intelligence><endpointUri>
.uri(URI.create("${diUrl}${endpointUri}"))
// set Content-Type header to application/json
.header(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE)
.header(HttpHeaders.AUTHORIZATION, "Bearer $accessToken")
// add the body
.POST(
// use empty body to sync all accounts
HttpRequest.BodyPublishers.ofString(body)
).build()
}
companion object {
private val log = KotlinLogging.logger { }
}
}
Next, we add to the class the method that will start the synchronization.
Since synchronizing a Data Source is an asynchronous process, we must first create an internal processId which we will use as a callbackHandle.
We can use this later to identify and continue our process again via the callback.
Since some calls require parameters, we should also store these at the processId before synchronizing the data source, so that the callback knows directly what it has to do.
For this we have the object DiProcessEntity, which we pass to the syncDataSource() function.
You can find the code of those classes in the repository.
After that, we send the request and use the previously created function createPostRequest() to create the request.
The result is checked in this example with a simple static function to see if it matches 2xx. Otherwise, an exception is thrown and the process is completely aborted.
If this check is also successful, the body of the response is mapped into an object, and the data is saved.
In this example, we save the access_token as well, because we use it later for the callback.
In a production application, this should be encrypted so that no one can gain access to the client's data.
The syncDataSource() method gets the callbackPath from outside.
Reason for that is, that we can create different callback paths for different scenarios (e.g. Reports or Checks).
@Service
class DataSourceService(
@Value("\${finapi.instances.dataintelligence.url}") private val diUrl: String,
@Value("\${exampleapp.instances.callback.url}") private val callbackUrl: String,
private val dataSourcesRepository: DataSourcesRepository,
private val diProcessesRepository: DiProcessesRepository,
private val objectMapper: ObjectMapper
) {
/**
* Synchronize the data sources.
*/
@Throws(RuntimeException::class)
fun syncDataSource(
accessToken: String,
callbackPath: String,
processEntity: DiProcessEntity
): BankConnectionsResultModel {
val client = HttpClient.newBuilder().build()
// create the body for the request
val body = DataSourceSyncRequestModel(
callbackUrl = URI("${callbackUrl}${callbackPath}"),
callbackHandle = processEntity.processId
)
// create a request object and send it to DI
val response = client.send(
// create request URI for https://<data_intelligence>/api/v1/dataSources/bankConnections/synchronization
createPostRequest(
accessToken = accessToken,
endpointUri = CreateAndGetReportService.URI_DATA_SOURCE,
body = objectMapper.writeValueAsString(body)
),
HttpResponse.BodyHandlers.ofString()
)
// check for status code is 2xx or log and throw an exception
StatusCodeCheckUtils.checkStatusCodeAndLogErrorMessage(
response = response,
errorMessage = "Unable to sync data source."
)
// return the object of the mapped result
val bankConnectionsResult = objectMapper.readValue(response.body(), BankConnectionsResultModel::class.java)
// save all data sources and the current token to the database.
// the token is required when the asynchronous request of the callback is received to continue the process.
if (bankConnectionsResult.bankConnections != null) {
processEntity.status = EnumProcessStatus.SYNC_STARTED
val dataSources: ArrayList<DataSourceEntity> = ArrayList()
bankConnectionsResult.bankConnections.forEach {
dataSources.add(
DataSourceEntity(
userId = accessToken,
dataSourceId = it.dataSourceId
)
)
}
val dataSourceEntities = dataSourcesRepository.saveAll(dataSources)
processEntity.dataSources.addAll(dataSourceEntities)
// save the accessToken, so that the callback can continue.
// please encrypt this in reality!
processEntity.accessToken = accessToken
diProcessesRepository.save(processEntity)
}
log.info { "[${processEntity.processId}] Synchronization with Data Intelligence started" }
return bankConnectionsResult
}
[...]
}
With this, we would now be able to create the Data Sources.
Example to sync data sources for Reports:
// create a process entity, which will be stored, if the sync call was successful
val processEntity = DiProcessEntity(
processId = UUID.randomUUID().toString(),
status = EnumProcessStatus.SYNC_CREATED
)
// start synchronizing data sources
dataSourceService.syncDataSource(
accessToken = accessToken,
callbackPath = "${ReportCallbackApi.URI_BASEPATH}${ReportCallbackApi.URI_CB_DATASOURCE_REPORTS}",
processEntity = processEntity
)
Example to sync data sources for Checks with parameters:
// create a process entity, which will be stored, if the sync call was successful
val processEntity = DiProcessEntity(
processId = UUID.randomUUID().toString(),
status = EnumProcessStatus.SYNC_CREATED,
amount = BigDecimal.ONE
)
// start synchronizing data sources
dataSourceService.syncDataSource(
accessToken = accessToken,
callbackPath = "${CheckCallbackApi.URI_BASEPATH}${CheckCallbackApi.URI_CB_DATASOURCE_CHECKS}",
processEntity = processEntity
)
It is important to note that we are referring to an implementation with callback here. Without callback, the state of the data source must be polled. This should always happen with a pause of at least 200ms. Only when the status is SUCCESSFUL may the creation of a case be continued.