Transactions alone are often just unstructured data sets that reveal little information about the customer's current life stage and financial situation.
Only by putting these transactions into context is it possible to understand what liabilities a customer has and in what areas the customer is spending.
What it solves
Transactions are primarily sets of data that do not usually provide specific context.
Labelling gives transactions this context via labels. This makes it possible to filter out special transactions, depending on the needs, for further logic.
Examples are finding out about insurances, loans, or other liabilities.
In addition, further data for specific transactions can be extracted via the Labelling Service. These are, for example, customer or contract numbers. To achieve optimal results, labeling is both keyword-based and AI-supported. The labeling process itself, as well as the underlying label set, is continuously refined and expanded. External modifications to the label set are not possible. Labeling represents a core component of our product portfolio, serving as the foundation upon which all of our solutions are built.
Labeling is currently available for German and Dutch language.
What are labels?
First, we need to explain the labels so that there is a basic understanding of what they do and how they relate to each other and to the transactions.
Labels are more a “sticker” on the transaction than a hierarchy, similar to labels in Gmail.
A transaction can have multiple labels, and it can happen that they are part of different label categories. Each label will be added to the transaction on the basis of expert rules.
All available expressions will be applied to all transactions, also if one fits already.

With this approach, labels contrast with classic categories, which act like structured drawers.
Once a transaction has been assigned to a category, it cannot be assigned to another category. Today's transactions, however, are far more complex and can be assigned to several areas, depending on their interest.
Labels vs. Categories
The difference between labels and categories is that categories are strictly hierarchical and transactions can only be assigned to one category.
Labels, on the other hand, are open and do not restrict what a transaction is assigned to.
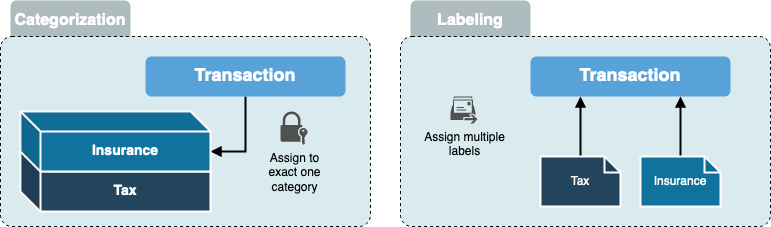
In the case of categorization, a transaction is assigned to a category. This is comparable to filing the transaction in paper form.
Once placed in a drawer, it cannot be placed in another drawer.
Labeling, on the other hand, goes the opposite way, since here you "stick" the context to the transaction instead of putting the transaction on top of the context.
This allows the labeling of a transaction to have multiple contexts.
As a simple example, one can take the tax return. In a categorization, I have to decide if I want to categorize a transaction, for example in insurance or in tax-relevant things.
The labeling makes it possible to assign both contexts to the transaction.
Depending on the situation, you can now search for tax-relevant transactions or for insurances.
With a categorization, you would have to search through all categories to see if a tax-relevant transaction is included.
Summary
-
Categorization means that a transaction can be assigned to exactly one context and does not allow for different perspectives
-
Labeling means assigning multiple contexts to the transaction for different perspectives
Level of Detail
However, our labels are not completely unstructured. They are divided into so-called "Levels of Detail" (LoD).
These give the unstructured labels a basic order. Depending on the label, this structure can be very flat (e.g., only 2 levels of detail) or very detailed (e.g., 4 levels of detail).
Level of Detail of the first level is quite unspecific (e.g., INSURANCE or BANKANDCREDIT). They reflect the basic character of the transaction and can serve as basic filters for applications.
A higher Level of Detail then details the transaction further to name it very specifically at the highest level.
Based on this example, it becomes clear quite quickly what is meant by further detailing:
-
LoD 1:
BANKANDCREDIT-
LoD 2:
BANKING-
LoD 3:
MONEY_TRANSFER-
LoD 4:
MONEY_TRANSFER_SPENDING
-
-
-
Example
Credit company A wants to know how many loans a customer has.
Insurance company B wants to know if the customer has cars to offer a product.
If we see in the transactions, that the customer has a car loan, we can label the transaction with:
-
LoD 1:
BANKANDCREDIT -
LoD 2:
LOANANDINTEREST -
LoD 3:
CARLOAN
This is very interesting for a credit company A.
But we also do add the label to LoD 1 MOBILITY, which is very interesting as a filter for insurance company B.
The result looks like this:
-
LoD 1:
BANKANDCREDIT-
LoD 2:
LOANANDINTEREST-
LoD 3:
CARLOAN
-
-
-
LoD 1:
MOBILITY-
LoD 2:
CARLOAN
-
With traditional categorization, it is only possible to assign the transaction to one path (BANKANDCREDIT OR MOBILITY).
Labelling allows both paths to be stored on the transaction and later selected based on interest.
Labelled Transactions
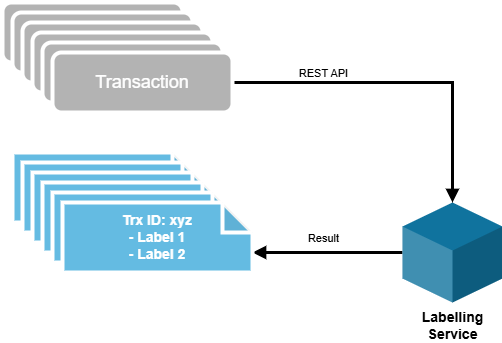
The core of Data Intelligence is the Labelled Transactions, which are created by the Labelling Service.
This service is designed to be neutral and can accept transactions from any source.
It does not save or load any data in the background, but accepts the incoming transactions, processes them and returns the resulting labels and data.
Used data fields
Labels are only as good as the source transaction is.
This means that the more data provided, the better the result.
A full API schema can be seen here: https://docs.finapi.io/?product=labelling#post-/labels/detailed
|
Field |
Description |
Mandatory |
|---|---|---|
|
|
ID of the transaction to be able to assign the result to the source |
yes |
|
|
ID of the account to be able to assign the result to the source |
yes |
|
|
Amount of the transaction |
yes |
|
|
The purpose is an important information for the labelling and is used to extract some additional data like customer number |
no |
|
|
The name of the counterpart is also an important indicator for some rules or for the selection of a subset of rules. |
no |
|
|
Bank type of the transaction (e.g. |
no |
|
|
ZKA business transaction code (1-999) defines the type of the transaction |
no |
|
|
SWIFT transaction type code |
no |
|
|
SEPA purpose code, according to ISO 20022 |
no |
|
|
Counterpart creditor identifier |
no |
|
|
Counterpart mandate reference |
no |
|
|
IBAN of the counterpart |
no |
|
|
BIC of the counterpart’s bank |
no |
|
|
IBAN of the user’s account |
no |
|
|
Account holder name |
no |