Introduction
Reports in finAPI Data Intelligence are special extracts from transactions with aggregated data.
They are designed to give a special view of the transactions of interest without having to find them out yourself.
The aggregations they contain also make it possible to quickly access the relevant data.
To generate a report, a data source and a case are always required.
These are always in the relationship Data Sources -> Case -> Reports.
For certain business requirements, it may be useful to create a Digital Account Check (DAC). This takes over the creation of the case and the reports automatically. However, the reports to be created are predefined.
More information:
Workflow as a real-world example
To explain this concept a bit more "plastic ", we could describe the workflow as follows:
-
As a customer of a company using Data Intelligence, I would like to conclude a contract for payment by installments.
-
I prepare my bank statements or account information at home and take them with me to the store where I want to conclude the installment contract.
-
→ SYNCHRONIZE DATA SOURCES after importing the account(s) in Access (via WF2.0)
-
-
The seller now wants to check my data, so he takes a folder, writes my name on it, and puts the account information I brought along as a copy. He then staples the originals to my customer account.
-
→ CREATE CASE
-
-
Depending on the amount I want to finance, he has to do different things on the basis of the data, such as a risk assessment, an income statement, etc. So he writes the required evaluations on a note, which he also puts in the folder.
-
→ ADD REPORT TO CASE
-
-
Now he passes the folder on to the finance department, which looks at the documents and creates the requested evaluations.
-
→ CREATE REPORT (happens in the background, as if I can not see what is happening in the office of the store)
-
-
The financing department now comes back to the seller, gives him the folder with the evaluations in it, and he can evaluate whether I can close the contract.
-
→ GET REPORT(s)
-
-
If he needs further evaluations due to the results (e.g. whether I play), he can add the additionally required evaluations to the folder and hand them over again to the financing department, which creates an additional evaluation.
-
→ ADD MORE REPORTS TO CASE
-
-
-
One month later, I want to finance something else. But this time the amount is much smaller.
-
The seller therefore only copies my account information of my salary account and attaches this to a new folder for the financing. The whole process now starts over again but uses my already known account information again.
-
→ CREATE NEW CASE (with existing data sources)
-
-
However, as the data is unfortunately no longer up to date, he asks me to update my account details for the account and bring new bank statements with me.
-
→ SYNCHRONIZE DATA SOURCE again after updating the account in Access (via WF2.0)
-
-
Prerequisites
-
The major prerequisite is to have a valid set of client credentials:
client_idandclient_secret. -
A user has already been created
-
With self-managed user: Getting Started - User Management
-
With Process Controller: Obtain Authorization via Process Controller (recommended)
-
-
At least one account has already been imported via finAPI WebForm 2.0 (see WebForm Documentation)
TL:TR
Used Systems
-
finAPI Data Intelligence (finAPI API Documentation )
See Environments page for detailed information.
Used Endpoints
To create a report, at least the following endpoints are required:
|
Description |
HTTP Method |
Process Controller Endpoint |
Link to API Doc |
|---|---|---|---|
|
Synchronize Data Source |
POST |
|
|
|
Get status of the Data Source
|
GET |
|
|
|
Create a case |
POST |
|
|
|
Create a report |
POST |
|
|
|
Get all reports |
GET |
|
|
|
Get a report (optional or for continuous reports) |
GET |
|
Process Overview
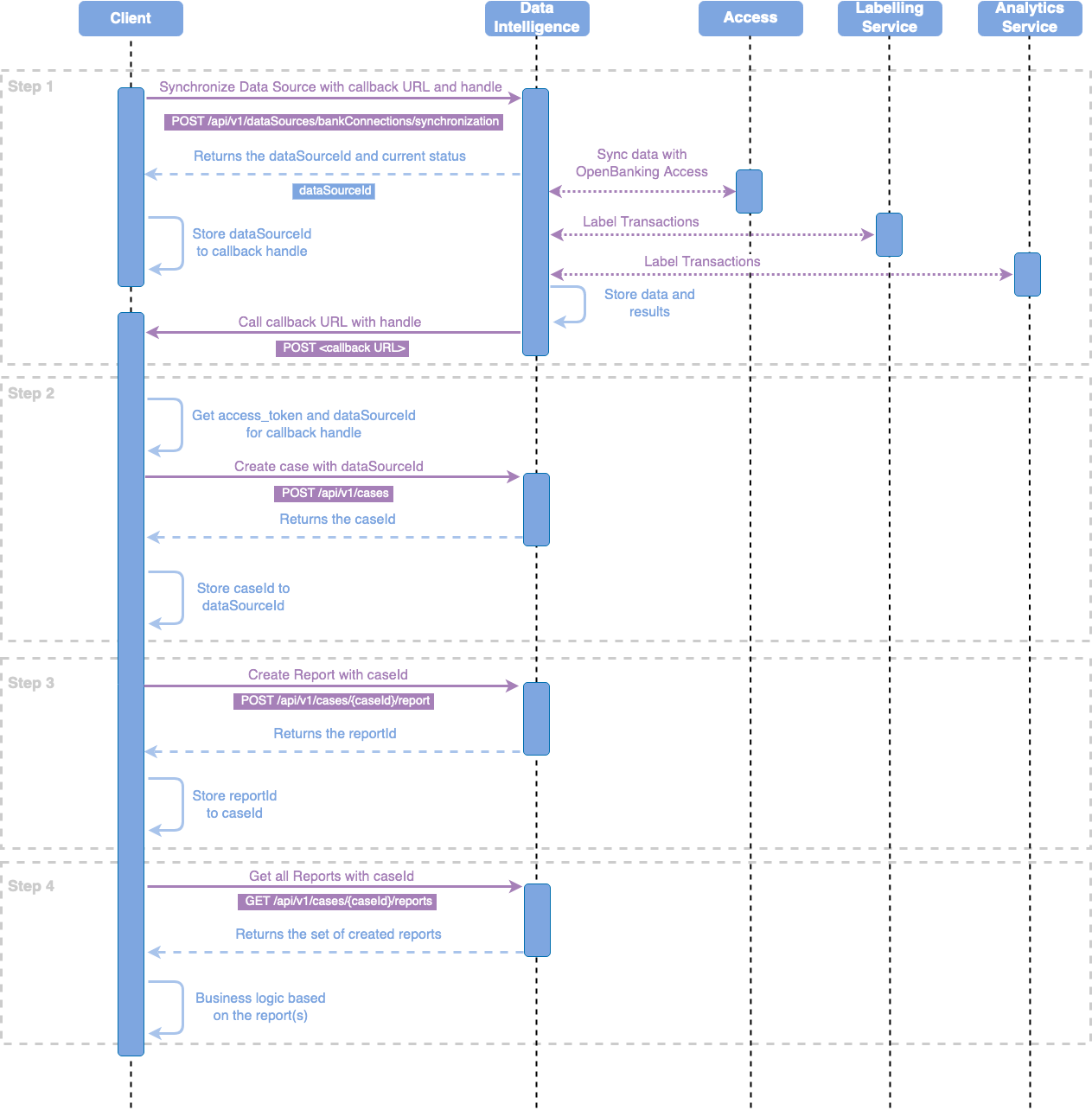
cURL Example
Translated into cURL it looks like the following:
Step 1 - Synchronize Data Source (cURL)
This step is an extract from the Guide for Cases. More information can be found at Getting Started - Synchronize a Data Source.
Before you can synchronize data in Data Intelligence, it must already have been imported via finAPI WebForm 2.0 or finAPI OpenBanking Access.
For synchronization, it is recommended that the callback is used to avoid unnecessary poll requests that can stress client and server systems.
Synchronization request example for full synchronization of the user:
curl --location 'https://di-sandbox.finapi.io/api/v1/dataSources/bankConnections/synchronization' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer <access_token>' \
--data '{
"callbackUrl": "https://domain.tld",
"callbackHandle": "38793e87-499d-4860-b947-2c2c8ab10322"
}'
The response looks like this:
{
"bankConnections": [
{
"dataSourceId": "4e760145-2e65-4242-ac33-488943528c93",
"creationDate": "2020-01-01 00:00:00.000",
"lastUpdate": "2020-01-01 00:00:00.000",
"externalId": 123456,
"bic": "COBADEFFXXX",
"bankName": "Commerzbank",
"bankStatus": "IN_PROGRESS",
"updateRequired": false,
"accounts": [
{
"accountId": "5f660145-2e65-4242-ac33-488943528c93",
"creationDate": "2020-01-01 00:00:00.000",
"lastUpdate": "2020-01-01 00:00:00.000",
"externalId": 123456,
"iban": "DE13700800000061110500",
"accountType": "CHECKING",
"status": "UPDATED"
}
]
}
]
}
Step 1.5 - Polling the status of the Data Source (cURL)
It is not recommended to poll the status. If you still want to do it, please make sure that there is at least a 200ms pause between requests.
Request to the Data Source status:
curl --location 'https://di-sandbox.finapi.io/api/v1/dataSources/{dataSourceId}/status' \
--header 'Authorization: Bearer <access_token>'
The response looks like this:
{
"status": "IN_PROGRESS",
"code": "SYNC_IN_PROGRESS",
}
As long as the status is not SUCCESSFUL, you cannot proceed with report creation.
Step 2 - Create a case (cURL)
This step is an extract from the Guide for Cases. More information can be found at Getting Started - Create a Case File .
A case requires one or more data sources. This allows the reports to know which accounts should be used.
It can also restrict the time period with maxDaysForCase or datePeriodForCase elements.
The withTransactions element can be used here to define the default behavior of the reports transaction output later.
Request to create a case with maxDaysForCase:
curl --location 'https://di-sandbox.finapi.io/api/v1/cases' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer <access_token>' \
--data '{
"dataSourceIds": [
"4e760145-2e65-4242-ac33-488943528c93"
],
"maxDaysForCase": 89,
"withTransactions": true
}'
Request to create a case with datePeriodForCase:
curl --location 'https://di-sandbox.finapi.io/api/v1/cases' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer <access_token>' \
--data '{
"dataSourceIds": [
"4e760145-2e65-4242-ac33-488943528c93"
],
"datePeriodForCase": {
"dateFrom": "2023-01-01",
"dateTo": "2023-02-01"
},
"withTransactions": true
}'
The response for maxDaysForCase looks like this:
{
"id": "0b5d1980-63ec-4f3c-bbcf-dd81b044d580",
"maxDaysForCase": 89,
"creationDate": "2023-02-01 00:00:00.000",
"dataSources": [
{
"id": "4e760145-2e65-4242-ac33-488943528c93",
"creationDate": "2020-01-01 00:00:00.000"
}
]
}
Step 3 - Create a report (cURL)
In this step, we can define which reports should be part of the case. This can be one or more.
Requests to create a report:
curl --location 'https://di-sandbox.finapi.io/api/v1/cases/0b5d1980-63ec-4f3c-bbcf-dd81b044d580/report' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer <access_token>' \
--data '{
"reportType": "BANKANDCREDIT"
}'
0b5d1980-63ec-4f3c-bbcf-dd81b044d580 in the path is the id of the case.
The result looks like this:
{
"id": "f8e82ccc-38d2-417f-adcc-d5569463f8eb"
}
This ID can be used to get only this report back.
Step 3.5 - Create a Continuous Report (cURL)
If you want to create a continuous report, then use the same endpoint, but extend the body with the continuousReport section. A previous report must be specified as parentReportId. The end date of the parent report determines the start date of the continuous report.
Request to create a continuous report:
curl --location 'https://di-sandbox.finapi.io/api/v1/cases/0b5d1980-63ec-4f3c-bbcf-dd81b044d580/report' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer <access_token>' \
--data '{
"reportType": "BANKANDCREDIT",
"continuousReport": {
"parentReportId": "f8e82ccc-38d2-417f-adcc-d5569463f8eb",
"endDate": "2023-06-26T06:15:59.547Z"
}
}'
The result is again only the ID of the report.
Step 4 - Get Reports (cURL)
Be aware, that get a report can respond with 423. In this case the report is not ready and must be polled.
To pick up reports there are 2 ways.
Either you use the Get all reports endpoint, which returns all reports in a large structure or you use the Get a report endpoint, which returns exactly one report.
To retrieve continuous reports the Get a report endpoint is needed. For all other reports we recommend Get all reports.
Request to get all reports:
curl --location 'https://di-sandbox.finapi.io/api/v1/cases/0b5d1980-63ec-4f3c-bbcf-dd81b044d580/reports' \
--header 'Authorization: Bearer <access_token>'
0b5d1980-63ec-4f3c-bbcf-dd81b044d580 in the path is the id of the case.
The result looks like this (shortened):
{
"caseId": "0b5d1980-63ec-4f3c-bbcf-dd81b044d580",
"reports": {
"bankAndCredit": {
"id": "f8e82ccc-38d2-417f-adcc-d5569463f8eb",
"creationDate": "2023-01-01 00:00:00.000",
"caseId": "0b5d1980-63ec-4f3c-bbcf-dd81b044d580",
"type": "BANKANDCREDIT",
"startDate": "2023-01-01 00:00:00.000",
"endDate": "2023-01-01 00:00:00.000",
"daysOfReport": 20,
"transactionsStartDate": "2023-01-01 00:00:00.000",
"totalTransactionsCount": 20,
"countIncomeTransactions": 17,
"countSpendingTransactions": 0,
"totalIncome": 150.75,
"totalSpending": 0,
"totalBalance": 150.75,
"accountData": [
{
"bankName": "Commerzbank",
"bankId": "4e760145-2e65-4242-ac33-488943528c93",
"accountIban": "DE13700800000061110500",
"accountId": "5f660145-2e65-4242-ac33-488943528c93",
"transactions": [
{
"valueDate": "2023-01-01 00:00:00.000",
"bankBookingDate": "2023-01-01 00:00:00.000",
"amount": -99.99,
"purpose": "Restaurantbesuch",
"counterpartName": "Bar Centrale",
"counterpartAccountNumber": "0061110500",
"counterpartIban": "DE13700800000061110500",
"counterpartBlz": "70080000",
"counterpartBic": "DRESDEFF700",
"counterpartBankName": "Commerzbank vormals Dresdner Bank",
"labels": [
"ENUMLABEL"
],
"overdraftInformation": {
"overdraftInterestAmount": 99.9,
"startDate": "1.1.2023",
"endDate": "28.3.2023"
},
"chargebackInformation": {
"chargebackAmount": 99.9,
"valueDate": "1.1.2023"
}
}
]
}
]
}
}
}
Step 4.5 - Get one Report (cURL)
Getting one report looks like this:
curl --location --globoff 'https://di-sandbox.finapi.io/api/v1/reports/f8e82ccc-38d2-417f-adcc-d5569463f8eb' \
--header 'Authorization: Bearer <access_token>'
f8e82ccc-38d2-417f-adcc-d5569463f8eb is the id of the report.
The result looks similar to the previous one, but it does not contain the caseId on the root level.
Implementation Guide
See a full working project here: finAPI Data Intelligence Product Platform Examples (Bitbucket)
Code from this guide can be found here: finAPI Data Sources(Bitbucket), finAPI Reports (Bitbucket)
Environment overview can be found here: Environments
The guidelines and the example project are written in Kotlin with Spring Boot. But it is easily adoptable for other languages and frameworks.
For the HTTP connection, we are using here plain Java HttpClient, to be not restrictive for the client selection and that everything is transparent.
Only the actual functionality is discussed in this guideline. Used helper classes or the models can be looked up in the source code.
However, we always recommend using a generated client from our API, which reduces the effort of creating models and functions to access the endpoints and eliminates potential sources of error.
To learn how to generate and apply the API client using the Process Controller "Create user and exchange with access_token" as an example, please see the Getting Started - Code Generator (SDK) Integration.
Please also note that the code presented here and also the repository is only an illustration of a possible implementation. Therefore, the code is kept very simple and should not be used 1:1 in a production environment.
Example Code Flow Description
The flow of this example is, that the application synchronizes the data source as soon as the user is done with his connection of the accounts in finAPI WebForm or finAPI OpenBanking Access.
Further processing is done asynchronously by the callback.
As soon as the callback arrives again, it is checked whether the result is positive.
If the callback is positive, the Case and Report are created in the background and the Report is retrieved.
We are working with status updates in the local database. This database should be polled or streamed by the (frontend) application, to know if an error happened in the background or if the user can continue, because everything was successful.
Step 1 - Synchronize Data Source
This step is an extract from the Guide for Data Sources. More information can be found at Getting Started - Synchronize a Data Source.
Data sources are a central component and not just bound to reports. Therefore we create them in a neutral datasourcespackage: finAPI Data Sources(Bitbucket) (Data Source)
In this step, we create a simple service that starts the synchronization. In addition, we use a callback so that we don't have to poll for synchronization status.
First, we create a new class named DataSourceService. This gets the URL of finAPI Data Intelligence (incl. the base path /api/v1) and the domain of the own service for the callback.
As further classes we get the DataSourcesRepository and DiProcessesRepository passed. These classes are example database repositories. In the example, these classes are not discussed further because they only perform the required tasks in the example.
Last but not least we have an ObjectMapper which is used to map JSON into objects and vice versa.
The first function we create is createPostRequest(). This is passed the user access_token, the URI of finAPI Data Intelligence, and the body.
From the URI and the diURL, which we get via the constructor and the configuration, the method builds the final URL.
@Service
class DataSourceService(
@Value("\${finapi.instances.dataintelligence.url}") private val diUrl: String,
@Value("\${exampleapp.instances.callback.url}") private val callbackUrl: String,
private val dataSourcesRepository: DataSourcesRepository,
private val diProcessesRepository: ReportProcessesRepository,
private val objectMapper: ObjectMapper
) {
/**
* Create a POST HttpRequest.
*/
private fun createPostRequest(
accessToken: String,
endpointUri: String,
body: String
): HttpRequest {
return HttpRequest.newBuilder()
// build URL for https://<data_intelligence><endpointUri>
.uri(URI.create("${diUrl}${endpointUri}"))
// set Content-Type header to application/json
.header(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE)
.header(HttpHeaders.AUTHORIZATION, "Bearer $accessToken")
// add the body
.POST(
// use empty body to sync all accounts
HttpRequest.BodyPublishers.ofString(body)
).build()
}
companion object {
private val log = KotlinLogging.logger { }
}
}
Next, we add to the class the method that will start the synchronization.
Since synchronizing a Data Source is an asynchronous process, we must first create an internal processId which we will use as a callbackHandle.
We can use this later to identify and continue our process again via the callback.
Since some calls require parameters, we should also store these at the processId before synchronizing the data source, so that the callback knows directly what it has to do.
For this we have the object DiProcessEntity, which we pass to the syncDataSource() function.
You can find the code of those classes in the repository.
After that, we send the request and use the previously created function createPostRequest() to create the request.
The result is checked in this example with a simple static function to see if it matches 2xx. Otherwise, an exception is thrown and the process is completely aborted.
If this check is also successful, the body of the response is mapped into an object, and the data is saved.
In this example, we save the access_token as well, because we use it later for the callback.
In a production application, this should be encrypted so that no one can gain access to the client's data.
The syncDataSource() method gets the callbackPath from outside.
Reason for that is, that we can create different callback paths for different scenarios (e.g. Reports or Checks).
@Service
class DataSourceService(
@Value("\${finapi.instances.dataintelligence.url}") private val diUrl: String,
@Value("\${exampleapp.instances.callback.url}") private val callbackUrl: String,
private val dataSourcesRepository: DataSourcesRepository,
private val diProcessesRepository: DiProcessesRepository,
private val objectMapper: ObjectMapper
) {
/**
* Synchronize the data sources.
*/
@Throws(RuntimeException::class)
fun syncDataSource(
accessToken: String,
callbackPath: String,
processEntity: DiProcessEntity
): BankConnectionsResultModel {
val client = HttpClient.newBuilder().build()
// create the body for the request
val body = DataSourceSyncRequestModel(
callbackUrl = URI("${callbackUrl}${callbackPath}"),
callbackHandle = processEntity.processId
)
// create a request object and send it to DI
val response = client.send(
// create request URI for https://<data_intelligence>/api/v1/dataSources/bankConnections/synchronization
createPostRequest(
accessToken = accessToken,
endpointUri = CreateAndGetReportService.URI_DATA_SOURCE,
body = objectMapper.writeValueAsString(body)
),
HttpResponse.BodyHandlers.ofString()
)
// check for status code is 2xx or log and throw an exception
StatusCodeCheckUtils.checkStatusCodeAndLogErrorMessage(
response = response,
errorMessage = "Unable to sync data source."
)
// return the object of the mapped result
val bankConnectionsResult = objectMapper.readValue(response.body(), BankConnectionsResultModel::class.java)
// save all data sources and the current token to the database.
// the token is required when the asynchronous request of the callback is received to continue the process.
if (bankConnectionsResult.bankConnections != null) {
processEntity.status = EnumProcessStatus.SYNC_STARTED
val dataSources: ArrayList<DataSourceEntity> = ArrayList()
bankConnectionsResult.bankConnections.forEach {
dataSources.add(
DataSourceEntity(
userId = accessToken,
dataSourceId = it.dataSourceId
)
)
}
val dataSourceEntities = dataSourcesRepository.saveAll(dataSources)
processEntity.dataSources.addAll(dataSourceEntities)
// save the accessToken, so that the callback can continue.
// please encrypt this in reality!
processEntity.accessToken = accessToken
diProcessesRepository.save(processEntity)
}
log.info { "[${processEntity.processId}] Synchronization with Data Intelligence started" }
return bankConnectionsResult
}
[...]
}
With this, we would now be able to create the Data Sources.
Example to sync data sources for Reports:
// create a process entity, which will be stored, if the sync call was successful
val processEntity = DiProcessEntity(
processId = UUID.randomUUID().toString(),
status = EnumProcessStatus.SYNC_CREATED
)
// start synchronizing data sources
dataSourceService.syncDataSource(
accessToken = accessToken,
callbackPath = "${ReportCallbackApi.URI_BASEPATH}${ReportCallbackApi.URI_CB_DATASOURCE_REPORTS}",
processEntity = processEntity
)
Example to sync data sources for Checks with parameters:
// create a process entity, which will be stored, if the sync call was successful
val processEntity = DiProcessEntity(
processId = UUID.randomUUID().toString(),
status = EnumProcessStatus.SYNC_CREATED,
amount = BigDecimal.ONE
)
// start synchronizing data sources
dataSourceService.syncDataSource(
accessToken = accessToken,
callbackPath = "${CheckCallbackApi.URI_BASEPATH}${CheckCallbackApi.URI_CB_DATASOURCE_CHECKS}",
processEntity = processEntity
)
It is important to note that we are referring to an implementation with callback here. Without callback, the state of the data source must be polled. This should always happen with a pause of at least 200ms. Only when the status is SUCCESSFUL may the creation of a case be continued.
The next step is to create the function for creating a case.
Step 2 - Create a case
This step is an extract from the Guide for Cases. More information can be found at Getting Started - Create a Case File .
Creating a case is the next step after creating a Data Source. First, we create a class called CaseService.
It requires the Data Intelligence URL, and our DiProcessesRepository, as well as the mandatory ObjectMapper.
We create a body for the case. We give it a list of the dataSourceIds, we’ve created and returned previously.
The dataSourceIds can also consist of accountId if a data source contains unwanted accounts. Internally, the system also resolves the data source to accounts.
If several data sources exist (e.g. a cash account and a joint account at different banks), all data source IDs can be specified.
All accounts will then be taken into consideration in the report.
The response is validated again. However, a possible exception is caught here in order to be able to store a clean error status (CASE_CREATION_FAILED) in the system. This can be very relevant in support cases.
Afterward, the original exception is thrown again.
If everything was ok, we update the status to CASE_CREATED and return the result, that we have access to the caseId in the caller function.
We need a createPostRequest() method here, which prepares the client request.
This could also be solved centrally, but here we use the methods in each class to make it a bit more understandable.
@Service
class CaseService(
@Value("\${finapi.instances.dataintelligence.url}") private val diUrl: String,
private val diProcessesRepository: DiProcessesRepository,
private val objectMapper: ObjectMapper
) {
/**
* Create a case.
*/
@Throws(RuntimeException::class)
fun createCaseFile(
accessToken: String,
dataSourceIds: List<String>,
processEntity: DiProcessEntity
): CaseResponseModel {
log.info { "[${processEntity.processId}] Starting create a case..." }
val client = HttpClient.newBuilder().build()
// create body for the case
val body = CaseRequestModel(
dataSourceIds = dataSourceIds,
withTransactions = true
)
// send request
val response = client.send(
// create request URI for https://<data_intelligence>/api/v1/cases
createPostRequest(
accessToken = accessToken,
endpointUri = URI_CASES,
body = objectMapper.writeValueAsString(body)
),
HttpResponse.BodyHandlers.ofString()
)
// check for status code is 2xx or log and throw an exception
try {
StatusCodeCheckUtils.checkStatusCodeAndLogErrorMessage(
response = response,
errorMessage = "Unable to create case."
)
} catch (@Suppress("TooGenericExceptionCaught") ex: RuntimeException) {
processEntity.status = EnumProcessStatus.CASE_CREATION_FAILED
diProcessesRepository.save(processEntity)
throw ex
}
// map the result
val caseResponse = objectMapper.readValue(response.body(), CaseResponseModel::class.java)
// save successful state for case creation
processEntity.status = EnumProcessStatus.CASE_CREATED
diProcessesRepository.save(processEntity)
log.info { "[${processEntity.processId}] Finished create a case..." }
return caseResponse
}
/**
* Create a POST HttpRequest.
*/
private fun createPostRequest(
accessToken: String,
endpointUri: String,
body: String
): HttpRequest {
return HttpRequest.newBuilder()
// build URL for https://<data_intelligence><endpointUri>
.uri(URI.create("${diUrl}${endpointUri}"))
// set Content-Type header to application/json
.header(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE)
.header(HttpHeaders.AUTHORIZATION, "Bearer $accessToken")
// add the body
.POST(
// use empty body to sync all accounts
HttpRequest.BodyPublishers.ofString(body)
).build()
}
companion object {
private val log = KotlinLogging.logger { }
const val URI_CASES = "/cases"
}
}
Now we have finished the function that can create the case.
Next, we take care of the report itself.
Step 3 - Create a Report
Creating a report works the same way as creating a case.
As parameters, we pass again an access_token, the processId, the caseId, and the type of report we want to create.
The body of the request contains the report type.
In the request URL, the caseId is inserted, to which the report should refer.
Again, we handle the HTTP status validation exception to be able to store a clean error code or the successful code.
The answer is returned again.
This function can also be extended to generate a Continuous Report. For this, only the reportId of the previous report must be passed and written into the body in the block continuousReport.
The endDate can be specified. If it is not used, the current date will be used.
@Service
@Suppress("TooGenericExceptionCaught")
class CreateAndGetReportService(
@Value("\${finapi.instances.dataintelligence.url}") private val diUrl: String,
private val diProcessesRepository: DiProcessesRepository,
private val caseService: CaseService,
private val objectMapper: ObjectMapper
) {
/**
* Create a report.
*/
@Throws(RuntimeException::class)
fun createReport(
accessToken: String,
caseId: String,
reportType: EnumReportType,
processEntity: DiProcessEntity
): ReportCreateResponseModel {
log.info { "[${processEntity.processId}] Starting create a ${reportType.name} report..." }
val client = HttpClient.newBuilder().build()
// create body for reports
val body = ReportCreateRequestModel(
reportType = reportType
)
// send the request
val response = client.send(
// create request URI for https://<data_intelligence>/api/v1/cases/{caseId}/report
createPostRequest(
accessToken = accessToken,
endpointUri = "${URI_CASES}/${caseId}${URI_REPORT}",
body = objectMapper.writeValueAsString(body)
),
HttpResponse.BodyHandlers.ofString()
)
// check for status code is 2xx or log and throw an exception
try {
StatusCodeCheckUtils.checkStatusCodeAndLogErrorMessage(
response = response,
errorMessage = "Unable to create report."
)
} catch (@Suppress("TooGenericExceptionCaught") ex: RuntimeException) {
processEntity!!.status = EnumProcessStatus.REPORT_CREATION_FAILED
diProcessesRepository.save(processEntity)
throw ex
}
// map the result
val reportResponse = objectMapper.readValue(response.body(), ReportCreateResponseModel::class.java)
// save successful state for case creation
processEntity!!.status = EnumProcessStatus.REPORT_CREATED
diProcessesRepository.save(processEntity)
log.info { "[${processEntity.processId}] Finished create a ${reportType.name} report..." }
return reportResponse
}
companion object {
private val log = KotlinLogging.logger { }
const val URI_DATA_SOURCE = "/dataSources/bankConnections/synchronization"
const val URI_CASES = "/cases"
const val URI_REPORT = "/report"
const val URI_REPORTS = "/reports"
const val POLLING_WAIT_TIME_IN_MS = 200L
val POLLING_TIMEOUT_IN_SECONDS = Duration.ofSeconds(5)
}
}
With this, all the necessary objects have been created and we can now build a function that retrieves the reports.
Step 4 - Get Reports
Be aware, that get a report can respond with 423. In this case the report is not ready and must be polled.
Now it is time to retrieve the reports.
For this, we first need a function that creates a GET request.
@Service
@Suppress("TooGenericExceptionCaught")
class CreateAndGetReportService(
@Value("\${finapi.instances.dataintelligence.url}") private val diUrl: String,
private val diProcessesRepository: DiProcessesRepository,
private val caseService: CaseService,
private val objectMapper: ObjectMapper
) {
/**
* Create a GET HttpRequest.
*/
private fun createGetRequest(
accessToken: String,
endpointUri: String
): HttpRequest {
return HttpRequest.newBuilder()
// build URL for https://<data_intelligence><endpointUri>
.uri(URI.create("${diUrl}${endpointUri}"))
// set Content-Type header to application/json
.header(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE)
.header(HttpHeaders.AUTHORIZATION, "Bearer $accessToken")
// add the body
.GET()
.build()
}
[...]
}
For polling, we can implement a generic function, which handles the 423 response properly:
@Service
@Suppress("TooGenericExceptionCaught")
class CreateAndGetReportService(
@Value("\${finapi.instances.dataintelligence.url}") private val diUrl: String,
private val diProcessesRepository: DiProcessesRepository,
private val caseService: CaseService,
private val objectMapper: ObjectMapper
) {
/**
* If the report returns 423 (Locked), we wait for 400ms and try again.
*/
fun fetchReportWithPolling(
accessToken: String,
endpoint: String,
processEntity: DiProcessEntity
): HttpResponse<String> {
val start = Instant.now()
var response = fetchReportWithClient(
accessToken = accessToken,
endpoint = endpoint
)
while (response.statusCode() == 423 && Duration.between(start, Instant.now()) < POLLING_TIMEOUT_IN_SECONDS) {
log.info {
"[${processEntity.processId}] Get Report(s) is locked (423). " +
"Polling again in ${POLLING_WAIT_TIME_IN_MS}ms..."
}
try {
// wait before next polling
Thread.sleep(POLLING_WAIT_TIME_IN_MS)
} catch (_: InterruptedException) {
Thread.currentThread().interrupt()
break
}
response = fetchReportWithClient(
accessToken = accessToken,
endpoint = endpoint
)
}
return response
}
fun fetchReportWithClient(
accessToken: String,
endpoint: String
): HttpResponse<String> {
val client = HttpClient.newBuilder().build()
return client.send(
createGetRequest(
accessToken = accessToken,
endpointUri = endpoint
),
HttpResponse.BodyHandlers.ofString()
)
}
[...]
}
The fetchReportWithPolling() function tries first to get an answer. In the best case, it is already a 200 response.
If it is 403, it waits a specified time and tries again until a defined timeout. This prevents to not run infinitely.
Now we build a fetchAllReports() function, which calls the endpoint Get all reports, and a fetchOneReport() function, which calls the endpoint Get a report. The result will be returned.
For the call Get all reports at the endpoint /api/v1/cases/{caseId}/reports we need the caseId. In the result, we will find all reports created in this case.
In the call Get a report at the endpoint /api/v1/reports/{reportId} we need the reportId. In the result, we will find exactly the report we created before. Continuous reports can also be retrieved using this function.
Again, we handle the exception from the HTTP status code validation and set the status of the process accordingly to REPORT_FETCH_FAILED in case of error or REPORT_FETCHED in case of success.
@Service
@Suppress("TooGenericExceptionCaught")
class CreateAndGetReportService(
@Value("\${finapi.instances.dataintelligence.url}") private val diUrl: String,
private val diProcessesRepository: DiProcessesRepository,
private val caseService: CaseService,
private val objectMapper: ObjectMapper
) {
/**
* Fetch all reports.
*/
@Throws(RuntimeException::class)
fun fetchAllReports(
accessToken: String,
caseId: String,
processEntity: DiProcessEntity
): ReportsCaseModel {
log.info { "[${processEntity.processId}] Starting fetch all reports for case ${caseId}..." }
val response = fetchReportWithPolling(
accessToken = accessToken,
endpoint = "${URI_CASES}/${caseId}${URI_REPORTS}?withTransactions=true",
processEntity = processEntity
)
// check for status code is 2xx or log and throw an exception
try {
StatusCodeCheckUtils.checkStatusCodeAndLogErrorMessage(
response = response,
errorMessage = "Unable to fetch reports."
)
} catch (@Suppress("TooGenericExceptionCaught") ex: RuntimeException) {
processEntity.status = EnumProcessStatus.REPORT_FETCH_FAILED
diProcessesRepository.save(processEntity)
throw ex
}
// map the result
val reports = objectMapper.readValue(response.body(), ReportsCaseModel::class.java)
// save successful state for fetching the report
processEntity.status = EnumProcessStatus.REPORT_FETCHED
diProcessesRepository.save(processEntity)
log.info { "[${processEntity.processId}] Finished fetch all reports for case ${caseId}..." }
return reports
}
/**
* Fetch one report.
*/
@Throws(RuntimeException::class)
fun fetchOneReport(
accessToken: String,
reportId: String,
processEntity: DiProcessEntity
): ReportsModel {
log.info { "[${processEntity.processId}] Starting fetch the report ${reportId}..." }
val response = fetchReportWithPolling(
accessToken = accessToken,
endpoint = "${URI_REPORTS}/${reportId}",
processEntity = processEntity
)
// check for status code is 2xx or log and throw an exception
try {
StatusCodeCheckUtils.checkStatusCodeAndLogErrorMessage(
response = response,
errorMessage = "Unable to fetch reports."
)
} catch (@Suppress("TooGenericExceptionCaught") ex: RuntimeException) {
processEntity.status = EnumProcessStatus.REPORT_FETCH_FAILED
diProcessesRepository.save(processEntity)
throw ex
}
// map the result
val report = objectMapper.readValue(response.body(), ReportsModel::class.java)
// save successful state for fetching the report
processEntity.status = EnumProcessStatus.REPORT_FETCHED
diProcessesRepository.save(processEntity)
log.info { "[${processEntity.processId}] Finished fetch the report ${reportId}..." }
return report
}
[...]
}
With this, we have created a complete service to synchronize data sources, create cases and reports, and retrieve the report afterward.
Now we create one last function that controls the whole process after synchronization.
Theoretically, this can also be implemented in the callback service, but the technicality fits more here and the callback service remains simple.
We call this function createCaseAndReports().
It ensures that the calls are always executed in the following order:
-
Create Case
-
Create Report
-
Fetch Report(s)
-
Save Report results in a local database
@Service
@Suppress("TooGenericExceptionCaught")
class CreateAndGetReportService(
@Value("\${finapi.instances.dataintelligence.url}") private val diUrl: String,
private val diProcessesRepository: DiProcessesRepository,
private val caseService: CaseService,
private val objectMapper: ObjectMapper
) {
/**
* create case and reports process flow.
*/
@Throws(RuntimeException::class)
fun createCaseAndReports(
accessToken: String,
processId: String,
dataSourceIds: List<String>
) {
// fetch the process entity and check if it is available.
val processEntity = diProcessesRepository.findFirstByProcessId(processId = processId)
?: throw IllegalArgumentException("Process ID not found.")
// first we create a case file
val caseFileResult = createCaseFile(
accessToken = accessToken,
dataSourceIds = dataSourceIds,
processEntity = processEntity
)
// then we create a report inside this case
// with the result we can fetch only this report or save the report id for later usage
val reportCreateResult = createReport(
accessToken = accessToken,
caseId = caseFileResult.id,
// Creating an income report for this example.
// The process is always the same for others.
reportType = EnumReportType.INCOME,
processEntity = processEntity
)
// Now we can fetch one report, we've created before
val report = fetchOneReport(
accessToken = accessToken,
reportId = reportCreateResult.id,
processEntity = processEntity
)
// Or we fetch all reports of the case
val reports = fetchAllReports(
accessToken = accessToken,
caseId = caseFileResult.id,
processEntity = processEntity
)
// save the result to the database and continue with own business logic
}
[...]
}
Step 5 - Callback Service
Now that all domain-oriented calls are ready, the callback can be implemented.
The callback is sent as a POST request. Therefore we build a @RestController with a @PostMapping to our base URL.
Since we get the callback handle in the body we don`t need a dynamic URL. However, you should be able to clearly distinguish from other callbacks and only handle callbacks for report creation here.
Our code must first check if the body contains a callbackHandle, which is our created processId. If it does not, we cannot associate it with any synchronization and must abort.
For this, we throw an exception so that this can at least be logged.
After that, we fetch the object belonging to the callback handle from the database and check again if an instance was found. If this is null an exception is also thrown.
As a last validation of the input data we check if the request.datasource.status is set to SUCCESSFUL (see validateDataSourceRequest() function).
If this is successful, the status of the Data Source is updated.
It may happen that multiple Data Sources need to be updated.
Therefore, we need a function that checks in the database all Data Sources belonging to the handle whether they all have the status SUCCESSFUL.
In this example, this has been greatly simplified by only setting the callbackReceived flag to true should the status of the Data Source be SUCCESSFUL.
The isAllCallbacksReceived() function then simply checks through whether all data sources belonging to the process have received their callback.
Only if this condition is successful, a report is generated.
For this, we call the function createCaseAndReports() which controls the whole further process.
@RestController
class ReportCallbackApi(
private val createAndGetReportService: CreateAndGetReportService,
private val dataSourcesRepository: DataSourcesRepository,
private val diProcessesRepository: DiProcessesRepository
) {
@Suppress("TooGenericExceptionThrown")
@PostMapping("${URI_BASEPATH}${URI_CB_DATASOURCE_REPORTS}")
fun dataSourceCallbackForReports(@RequestBody body: CallbackRequestModel) {
// if the body does not contain a callback handle we throw an exception,
// because we cannot assign it to another request
if (body.callbackHandle == null) {
throw RuntimeException("No callback handle provided.")
}
// if we could not find the handle we do the same
val reportProcessEntity = diProcessesRepository.findFirstByProcessId(
processId = body.callbackHandle
) ?: throw RuntimeException("Unable to find the callback handle.")
// validate if the request contains a successful state or something else
if (validateDataSourceRequest(body)) {
// that we've received a data source
val dataSources = reportProcessEntity.dataSources
dataSources.forEach {
if (it.dataSourceId == body.datasourceId) {
it.callbackReceived = true
dataSourcesRepository.save(it)
}
}
// if everything was updated, we can create the case
if (isAllCallbacksReceived(dataSources = dataSources)) {
// figure out all data source ids
val dataSourceIds = ArrayList<String>()
reportProcessEntity.dataSources.forEach {
dataSourceIds.add(it.dataSourceId)
}
// call the "create case and reports" function
createAndGetReportService.createCaseAndReports(
accessToken = reportProcessEntity.accessToken,
processId = body.callbackHandle,
dataSourceIds = dataSourceIds
)
}
} else {
log.error{
"""
[${body.callbackHandle}] has received the status [${body.datasource?.status}]
with the code [${body.datasource?.code}]
and message [${body.datasource?.message}]
""".trimIndent()
}
// if the callback was not successful, we store it as error status
reportProcessEntity.status = EnumProcessStatus.CALLBACK_FAILED
diProcessesRepository.save(reportProcessEntity)
}
}
private fun isAllCallbacksReceived(dataSources: List<DataSourceEntity>): Boolean {
var result = true
dataSources.forEach {
if (!it.callbackReceived) {
result = false
}
}
return result
}
private fun validateDataSourceRequest(request: CallbackRequestModel) : Boolean {
return (request.callbackHandle != null &&
request.datasourceId != null &&
request.datasource != null &&
EnumStatus.SUCCESSFUL == request.datasource.status)
}
companion object {
private val log = KotlinLogging.logger { }
const val URI_BASEPATH = "/callbacks"
const val URI_CB_DATASOURCE_REPORTS = "/dataSource/reports"
}
}